
Foundry Localとは?
※ 本記事執筆時点の Foundry Local はパブリック プレビュー リリースのため、GA(一般提供)版と異なる可能性があります。
2025/05/19に発表されたMicrosoftのFoundry Localは、Azure AI FoundryのオープンソースモデルをローカルPCで実行できる。
公式発表:
Unlock Instant On-Device AI with Foundry Local | Azure AI Foundry Blog
公式ドキュメント:
Foundry Local のドキュメント
つまり、
- OllamaやLM StudioのようにローカルでLLM(SLM)を実行できる
- ローカル実行 = モデルのダウンロード以降はオフラインで使える
- モデル形式はONNX
- 対象モデルはAzure AI Foundry Catalog のオープンソースモデル
- Windows11だけじゃなくmacOSでも使える
試した環境
- Apple Macbook Air
- CPU: Apple M2
- GPU: Apple M2
- Mem: 16 GB
- OS: Sequoia 15.5
- HP Victus 16
- CPU: AMD Ryzen 7 5800H with Radeon Graphics 3.20 GHz
- GPU: NVIDIA GeForce RTX 3060 Laptop GPU
- Mem: 16 GB
- OS: Windows 11 Home 24H2
試してみる
インストール
公式手順どおり
Windows版とmacOS版のモデル比較
使えるモデルに若干違いがあるね。
Windows11でモデル一覧表示
PS C:\Users\nissy> foundry model list
🟢 Service is Started on http://localhost:5273, PID 30468!
Alias Device Task File Size License Model ID
-----------------------------------------------------------------------------------------------
phi-4 GPU chat-completion 8.37 GB MIT Phi-4-cuda-gpu
GPU chat-completion 8.37 GB MIT Phi-4-generic-gpu
CPU chat-completion 10.16 GB MIT Phi-4-generic-cpu
--------------------------------------------------------------------------------------------------------
phi-3-mini-128k GPU chat-completion 2.13 GB MIT Phi-3-mini-128k-instruct-cuda-gpu
GPU chat-completion 2.13 GB MIT Phi-3-mini-128k-instruct-generic-gpu
CPU chat-completion 2.54 GB MIT Phi-3-mini-128k-instruct-generic-cpu
---------------------------------------------------------------------------------------------------------------------------
phi-3-mini-4k GPU chat-completion 2.13 GB MIT Phi-3-mini-4k-instruct-cuda-gpu
GPU chat-completion 2.13 GB MIT Phi-3-mini-4k-instruct-generic-gpu
CPU chat-completion 2.53 GB MIT Phi-3-mini-4k-instruct-generic-cpu
-------------------------------------------------------------------------------------------------------------------------
mistral-7b-v0.2 GPU chat-completion 3.98 GB apache-2.0 mistralai-Mistral-7B-Instruct-v0-2-cuda-gpu
GPU chat-completion 4.07 GB apache-2.0 mistralai-Mistral-7B-Instruct-v0-2-generic-gpu
CPU chat-completion 4.07 GB apache-2.0 mistralai-Mistral-7B-Instruct-v0-2-generic-cpu
-------------------------------------------------------------------------------------------------------------------------------------
phi-3.5-mini GPU chat-completion 2.13 GB MIT Phi-3.5-mini-instruct-cuda-gpu
GPU chat-completion 2.16 GB MIT Phi-3.5-mini-instruct-generic-gpu
CPU chat-completion 2.53 GB MIT Phi-3.5-mini-instruct-generic-cpu
------------------------------------------------------------------------------------------------------------------------
phi-4-mini-reasoning GPU chat-completion 3.15 GB MIT Phi-4-mini-reasoning-cuda-gpu
GPU chat-completion 3.15 GB MIT Phi-4-mini-reasoning-generic-gpu
CPU chat-completion 4.52 GB MIT Phi-4-mini-reasoning-generic-cpu
-----------------------------------------------------------------------------------------------------------------------
deepseek-r1-14b GPU chat-completion 9.83 GB MIT deepseek-r1-distill-qwen-14b-cuda-gpu
GPU chat-completion 10.27 GB MIT deepseek-r1-distill-qwen-14b-generic-gpu
CPU chat-completion 11.51 GB MIT deepseek-r1-distill-qwen-14b-generic-cpu
-------------------------------------------------------------------------------------------------------------------------------
deepseek-r1-7b GPU chat-completion 5.28 GB MIT deepseek-r1-distill-qwen-7b-cuda-gpu
GPU chat-completion 5.58 GB MIT deepseek-r1-distill-qwen-7b-generic-gpu
CPU chat-completion 6.43 GB MIT deepseek-r1-distill-qwen-7b-generic-cpu
------------------------------------------------------------------------------------------------------------------------------
phi-4-mini GPU chat-completion 3.60 GB MIT Phi-4-mini-instruct-cuda-gpu
GPU chat-completion 3.72 GB MIT Phi-4-mini-instruct-generic-gpu
CPU chat-completion 4.80 GB MIT Phi-4-mini-instruct-generic-cpu
----------------------------------------------------------------------------------------------------------------------
qwen2.5-0.5b GPU chat-completion 0.52 GB apache-2.0 qwen2.5-0.5b-instruct-cuda-gpu
GPU chat-completion 0.68 GB apache-2.0 qwen2.5-0.5b-instruct-generic-gpu
CPU chat-completion 0.80 GB apache-2.0 qwen2.5-0.5b-instruct-generic-cpu
------------------------------------------------------------------------------------------------------------------------
qwen2.5-coder-0.5b GPU chat-completion 0.52 GB apache-2.0 qwen2.5-coder-0.5b-instruct-cuda-gpu
GPU chat-completion 0.52 GB apache-2.0 qwen2.5-coder-0.5b-instruct-generic-gpu
CPU chat-completion 0.80 GB apache-2.0 qwen2.5-coder-0.5b-instruct-generic-cpu
------------------------------------------------------------------------------------------------------------------------------
qwen2.5-1.5b GPU chat-completion 1.25 GB apache-2.0 qwen2.5-1.5b-instruct-cuda-gpu
GPU chat-completion 1.51 GB apache-2.0 qwen2.5-1.5b-instruct-generic-gpu
CPU chat-completion 1.78 GB apache-2.0 qwen2.5-1.5b-instruct-generic-cpu
------------------------------------------------------------------------------------------------------------------------
qwen2.5-7b GPU chat-completion 4.73 GB apache-2.0 qwen2.5-7b-instruct-cuda-gpu
GPU chat-completion 5.20 GB apache-2.0 qwen2.5-7b-instruct-generic-gpu
CPU chat-completion 6.16 GB apache-2.0 qwen2.5-7b-instruct-generic-cpu
----------------------------------------------------------------------------------------------------------------------
qwen2.5-coder-1.5b GPU chat-completion 1.25 GB apache-2.0 qwen2.5-coder-1.5b-instruct-cuda-gpu
GPU chat-completion 1.25 GB apache-2.0 qwen2.5-coder-1.5b-instruct-generic-gpu
CPU chat-completion 1.78 GB apache-2.0 qwen2.5-coder-1.5b-instruct-generic-cpu
------------------------------------------------------------------------------------------------------------------------------
qwen2.5-coder-7b GPU chat-completion 4.73 GB apache-2.0 qwen2.5-coder-7b-instruct-cuda-gpu
GPU chat-completion 4.73 GB apache-2.0 qwen2.5-coder-7b-instruct-generic-gpu
CPU chat-completion 6.16 GB apache-2.0 qwen2.5-coder-7b-instruct-generic-cpu
----------------------------------------------------------------------------------------------------------------------------
qwen2.5-14b GPU chat-completion 8.79 GB apache-2.0 qwen2.5-14b-instruct-cuda-gpu
GPU chat-completion 9.30 GB apache-2.0 qwen2.5-14b-instruct-generic-gpu
CPU chat-completion 11.06 GB apache-2.0 qwen2.5-14b-instruct-generic-cpu
-----------------------------------------------------------------------------------------------------------------------
qwen2.5-coder-14b GPU chat-completion 8.79 GB apache-2.0 qwen2.5-coder-14b-instruct-cuda-gpu
GPU chat-completion 8.79 GB apache-2.0 qwen2.5-coder-14b-instruct-generic-gpu
CPU chat-completion 11.06 GB apache-2.0 qwen2.5-coder-14b-instruct-generic-cpu
macOSでモデル一覧表示
nissy@MacBook-Air ~ % foundry model list
🟢 Service is Started on http://localhost:5273, PID 60770!
Alias Device Task File Size License Model ID
-----------------------------------------------------------------------------------------------
phi-4 GPU chat-completion 8.37 GB MIT Phi-4-generic-gpu
CPU chat-completion 10.16 GB MIT Phi-4-generic-cpu
--------------------------------------------------------------------------------------------------------
mistral-7b-v0.2 GPU chat-completion 4.07 GB apache-2.0 mistralai-Mistral-7B-Instruct-v0-2-generic-gpu
CPU chat-completion 4.07 GB apache-2.0 mistralai-Mistral-7B-Instruct-v0-2-generic-cpu
-------------------------------------------------------------------------------------------------------------------------------------
phi-3.5-mini GPU chat-completion 2.16 GB MIT Phi-3.5-mini-instruct-generic-gpu
CPU chat-completion 2.53 GB MIT Phi-3.5-mini-instruct-generic-cpu
------------------------------------------------------------------------------------------------------------------------
phi-3-mini-128k GPU chat-completion 2.13 GB MIT Phi-3-mini-128k-instruct-generic-gpu
CPU chat-completion 2.54 GB MIT Phi-3-mini-128k-instruct-generic-cpu
---------------------------------------------------------------------------------------------------------------------------
phi-3-mini-4k GPU chat-completion 2.13 GB MIT Phi-3-mini-4k-instruct-generic-gpu
CPU chat-completion 2.53 GB MIT Phi-3-mini-4k-instruct-generic-cpu
-------------------------------------------------------------------------------------------------------------------------
phi-4-mini-reasoning GPU chat-completion 3.15 GB MIT Phi-4-mini-reasoning-generic-gpu
CPU chat-completion 4.52 GB MIT Phi-4-mini-reasoning-generic-cpu
-----------------------------------------------------------------------------------------------------------------------
deepseek-r1-14b GPU chat-completion 10.27 GB MIT deepseek-r1-distill-qwen-14b-generic-gpu
-------------------------------------------------------------------------------------------------------------------------------
deepseek-r1-7b GPU chat-completion 5.58 GB MIT deepseek-r1-distill-qwen-7b-generic-gpu
------------------------------------------------------------------------------------------------------------------------------
phi-4-mini GPU chat-completion 3.72 GB MIT Phi-4-mini-instruct-generic-gpu
----------------------------------------------------------------------------------------------------------------------
qwen2.5-0.5b GPU chat-completion 0.68 GB apache-2.0 qwen2.5-0.5b-instruct-generic-gpu
CPU chat-completion 0.80 GB apache-2.0 qwen2.5-0.5b-instruct-generic-cpu
------------------------------------------------------------------------------------------------------------------------
qwen2.5-coder-0.5b GPU chat-completion 0.52 GB apache-2.0 qwen2.5-coder-0.5b-instruct-generic-gpu
CPU chat-completion 0.80 GB apache-2.0 qwen2.5-coder-0.5b-instruct-generic-cpu
------------------------------------------------------------------------------------------------------------------------------
qwen2.5-1.5b GPU chat-completion 1.51 GB apache-2.0 qwen2.5-1.5b-instruct-generic-gpu
CPU chat-completion 1.78 GB apache-2.0 qwen2.5-1.5b-instruct-generic-cpu
------------------------------------------------------------------------------------------------------------------------
qwen2.5-7b GPU chat-completion 5.20 GB apache-2.0 qwen2.5-7b-instruct-generic-gpu
CPU chat-completion 6.16 GB apache-2.0 qwen2.5-7b-instruct-generic-cpu
----------------------------------------------------------------------------------------------------------------------
qwen2.5-coder-1.5b GPU chat-completion 1.25 GB apache-2.0 qwen2.5-coder-1.5b-instruct-generic-gpu
CPU chat-completion 1.78 GB apache-2.0 qwen2.5-coder-1.5b-instruct-generic-cpu
------------------------------------------------------------------------------------------------------------------------------
qwen2.5-coder-7b GPU chat-completion 4.73 GB apache-2.0 qwen2.5-coder-7b-instruct-generic-gpu
CPU chat-completion 6.16 GB apache-2.0 qwen2.5-coder-7b-instruct-generic-cpu
----------------------------------------------------------------------------------------------------------------------------
qwen2.5-14b GPU chat-completion 9.30 GB apache-2.0 qwen2.5-14b-instruct-generic-gpu
CPU chat-completion 11.06 GB apache-2.0 qwen2.5-14b-instruct-generic-cpu
-----------------------------------------------------------------------------------------------------------------------
qwen2.5-coder-14b GPU chat-completion 8.79 GB apache-2.0 qwen2.5-coder-14b-instruct-generic-gpu
CPU chat-completion 11.06 GB apache-2.0 qwen2.5-coder-14b-instruct-generic-cpuß
コマンドラインから使ってみる。
ollama run phi4-mini みたいにコマンドラインからチャットできる。
PS C:\Users\nissy> foundry model run Phi-4-mini-instruct-cuda-gpu
Model Phi-4-mini-instruct-cuda-gpu was found in the local cache.
🕛 Loading model...
🟢 Model Phi-4-mini-instruct-cuda-gpu loaded successfully
Interactive Chat. Enter /? or /help for help.
Interactive mode, please enter your prompt
> 次のオリンピックはいつ、どこで?
🤖 2022年のオリンピックは、2022年7月23日から8月8日まで日本の東京で開催されました。これは、東京が2020年のオリンピックの
開催地として選ばれた後、2020年のオリンピックを中止し、2022年に開催することになったためです。
> /exit
PS C:\Users\nissy>
知識のカットオフは2021年だけど、そもそも間違ってる…
- 2022年は冬季オリンピックで2月4日から2月20日まで、開催地は北京
- 2020年の東京オリンピックは2021年に延期
貧弱なローカルPCで動かせるLLMというかSLMではこんなものなのよね…AI PC欲しい。
VS Code拡張機能のContinueで使ってみる
サービスが動いているか確認。
PS C:\Users\nissy> foundry service status
🟢 Model management service is running on http://localhost:5273/openai/status
停止しているとこんなメッセージが出るので、
PS C:\Users\nissy> foundry service status
🔴 Model management service is not running!
To start the service, run the following command: foundry service start
そんな時は開始する。
PS C:\Users\nissy> foundry service start
🟢 Service is Started on http://localhost:5273, PID 43332!
PS C:\Users\nissy> foundry service status
🟢 Model management service is running on http://localhost:5273/openai/status
ダウンロード済みモデルの確認は foundry cache ls
PS C:\Users\nissy> foundry cache ls
Models cached on device:
Alias Model ID
💾 phi-4-mini Phi-4-mini-instruct-cuda-gpu
ContinueのGUI設定からはFoundary Localを追加できないけど、OpenAI API互換なので、
PS C:\Users\nissy> curl http://127.0.0.1:5273/v1/models
{"data":[{"id":"Phi-4-mini-instruct-cuda-gpu","owned_by":null,"permission":[],"created":0,"CreatedTime":"1970-01-01T00:00:00+00:00","root":null,"parent":null,"StreamEvent":null,"IsDelta":false,"Successful":true,"error":null,"HttpStatusCode":0,"HeaderValues":null,"object":"model"}],"StreamEvent":null,"IsDelta":false,"Successful":true,"error":null,"HttpStatusCode":0,"HeaderValues":null,"object":"list"}
config.jsonにこんな感じで書けば使える。
おまけの比較用にOllamaとLM Studioの設定も書いておく。
{
"models": [
{
"title": "LM Studio",
"model": "phi-4-mini-instruct",
"provider": "lmstudio",
"apiBase": "http://127.0.0.1:1234/v1/"
},
{
"title": "Ollama",
"model": "phi4-mini",
"provider": "ollama",
"apiBase": "http://127.0.0.1:11434/"
},
{
"title": "Foundry Local",
"model": "Phi-4-mini-instruct-cuda-gpu",
"provider": "openai",
"apiBase": "http://127.0.0.1:5273/v1",
"apiKey": "dummy"
}
],
同じ質問をしてみると…あら?コマンドラインから尋ねた時と違う回答だ。
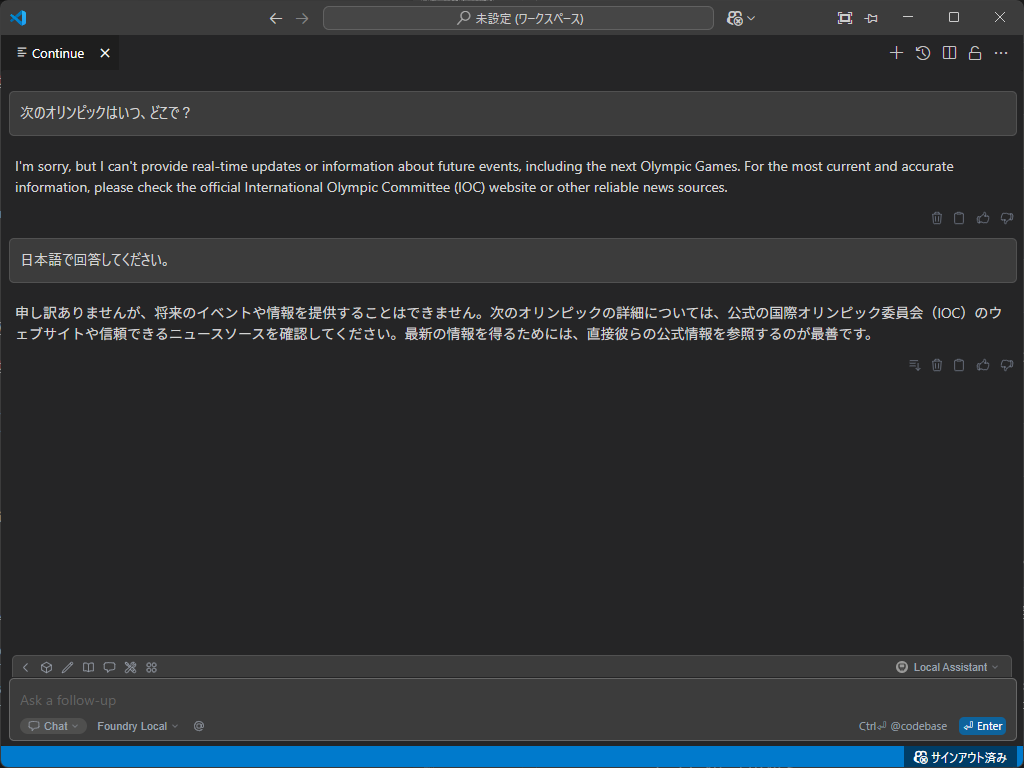
OllamaやLM Studioとは違った使い方ができるはずだけど、そっち方向はまだ良く分からない…